

 Abstract
Abstract HTML
HTML Reference
Reference Related
Related PDF
PDF











-
The Standard Model (SM) of electroweak interactions is based on the
$ SU(2)_L \times U(1)_Y $ gauge group [1-3], which determines the set of the gauge boson fields. However, the gauge group alone does not imply uniquely what kind and range of elementary particles can exist in nature [4]. The set of matter fields presently considered to be the elementary particles is based on a great number of experimental insights which are the results of long-standing research programs. It should hence be noted that experimental observations are the deciding factor in choosing the matter content that makes up the theory of elementary particles. Any hypothetical signals that could not be explained by the SM, like lepton violating processes, would need modification of the matter content and interactions. That choice must be based on experimental evidence.As far as neutrinos are concerned, at present there are known to be three neutrinos of different flavours, to which the three charged leptons correspond. The existence of the three light neutrino species has been known since the time of LEP. The central value for the effective number of light neutrinos,
$ N_\nu $ , was determined by analyzing around 20 million Z-boson decays, yielding$ N_\nu = 2.9840 \pm 0.0082 $ [5,6]. It is worth mentioning that the recent reevaluation of the data [7,8], including higher order QED corrections to the Bhabha process, further constrain the value of$ N_\nu $ , which is now$ N_\nu = 2.9963 \pm 0.0074 $ . The new$ N_\nu $ value is much closer to 3. Including shrinkage of the error, it leaves less space for non-standard neutrino mixings. In fact, a natural extension of the SM by right-handed neutrinos leads to a theoretical prediction with$ N_\nu $ less than three [9], assuming that there are non-zero mixings of active and sterile neutrinos, which implies non-unitarity of the matrix responsible for mixings among three known neutrino states. This can be seen from the general neutrino mixing setting. Let us denote a three-dimensional space which describes known neutrino mass and flavor states by${{ \big| {\nu^{(m)}_{\alpha}} \big\rangle} }$ and${ { \big| {\nu^{(f)}_{\alpha}} \big\rangle} }$ , respectively. Any extra, beyond SM (BSM) mass and flavor states we denote by${ \big| {\widetilde \nu^{(m)}_{j}} \big\rangle}$ and${\big| {\widetilde\nu^{(f)}_{j}} \big\rangle}$ for$ j = 1,\ldots, n_R $ , respectively. In this general scenario, mixing between an extended set of neutrino mass states${{ \{\big| {\nu^{(m)}_{\alpha}} \big\rangle},\big| {\widetilde \nu^{(m)}_{\beta}} \big\rangle}\}$ with flavor states${{ \{\big| {\nu^{(f)}_{\alpha}} \big\rangle},\big| {\widetilde\nu^{(f)}_{\beta}} \big\rangle}\}$ is described by$ \begin{pmatrix}{ { \big| {\nu^{(f)}_{\alpha}} \big\rangle}} \\ {\big| {\widetilde\nu^{(f)}_{\beta}} \big\rangle}\end{pmatrix} = \begin{pmatrix} {{ {\rm{U_{PMNS}}} }} & V_{lh} \\ V_{hl} & V_{hh} \end{pmatrix} \begin{pmatrix}{{\big| {\nu^{(m)}_{\alpha}} \big\rangle} } \\ {\big| {\widetilde \nu^{(m)}_{\beta}} \big\rangle}\end{pmatrix} \equiv U \begin{pmatrix} {{ {\big| {\nu^{(m)}_{\alpha}} \big\rangle} }} \\{ \big| {\widetilde \nu^{(m)}_{\beta}} \big\rangle}\end{pmatrix}\;. $

(1) The observable part of the above is the transformation from mass
${\big| {\nu^{(m)}_{\alpha}} \big\rangle}, {\big| {\widetilde \nu^{(m)}_{\beta}} \big\rangle}$ to SM flavor${\big| {\nu^{(f)}_{\alpha}} \big\rangle}$ states and reads$\big| {\nu _\alpha ^{(f)}} \big\rangle = \sum\limits_{i = 1}^3 {\underbrace {{{\left( {{{\rm{U}}_{{\rm{PMNS}}}}} \right)}_{\alpha i}}\big| {\nu _i^{(m)}} \big\rangle }_{{\rm{SM}}\;{\rm{part}}}} + \sum\limits_{j = 1}^{{n_R}} {\underbrace {{{\left( {{V_{lh}}} \right)}_{\alpha j}}\big| {\tilde \nu _j^{(m)}} \big\rangle }_{{\rm{BSM}}\;{\rm{part}}}} \;.$

(2) If
${{U_{\rm PMNS}}}$ is not unitary then there is necessarily a light-heavy neutrino "coupling" and the mixing between sectors is nontrivial,$ V_{lh} \neq 0 \neq V_{hl} $ . As U in Eq. (1) is unitary, and we know from neutrino oscillation experiments that the${{U_{\rm PMNS}}}{}$ matrix① [10,11] is unitary, within experimental accuracy, it follows that the elements of the non-diagonal matrices$ V_{lh}, V_{hl} $ in Eq. (1) which are responsible for the mixings of known neutrinos with extra states must be very small.There is a natural explanation of the above structure of
${{U_{\rm PMNS}}}$ and$ V_{lh},V_{hl} $ matrices, and it comes with the celebrated seesaw mechanism which in the first place explains the small masses of known neutrinos. This mechanism also justifies the introduction of the indices "l" and "h" in Eq. (1), which stand for "light" and "heavy," as usually we expect extra neutrino species to be much heavier than known neutrinos.To get physical masses, in the seesaw mechanism, the unitary matrix U in Eq. (1) is used to diagonalize the general neutrino mass matrix
$ M_{SS} = \left( \begin{array}{cc} M_L & M_{D} \\ M_{D}^T & M_{R} \end{array} \right) , $

(3) using a congruence transformation
$ U^{T}M_{SS}U \simeq {\rm diag}(M_{\rm light}, M_{\rm heavy}). $

(4) The exact form and origin of the neutrino mass matrices
$ M_L, M_D $ and$ M_R $ are not relevant now. They will be specified in the next section. In general, with the assumption that$ M_L = 0 $ , and$|m_D|\ll |m_R| , $

(5) which means that the elements of
$ M_D $ are much smaller than the elements of$ M_R $ with respect to absolute values, where$ \vert \cdot \vert $ in the case of matrices denotes absolute values of elements,$\begin{array}{l} M_{\rm light} \simeq -M_{D}M_{R}^{-1}M_{D}^{T}, \end{array} $

(6) $ \begin{array}{l} M_{\rm heavy} \simeq M_{R}. \end{array} $

(7) In Eq. (5) we use the lowercase letter m for the elements of a given matrix M. This convention will be applied thoughout the paper.
A large scale of
$ M_R $ makes$M_{\rm light}$ small, which represents the main idea of the seesaw mechanism.This mechanism was proposed for the first time by Minkowski in 1977 [12]. It originates from the idea of a Grand Unified Theory in which heavy neutrino mass states are present. Such neutrinos are supposed to be sterile, i.e. they are insensitive with respect to the weak interaction. In Ref. [12] a model based on
$ SU(2)_{L} \times SU(2)_{R} \times U(1) $ gauge symmetry was considered with its consequences for$ \mu \rightarrow e\gamma $ decays. At that time only 2 fermion families were under consideration, but both the seesaw mass matrix and famous seesaw formulas were introduced. Afterwards, similar models of neutrino mass generation were discussed in 1979 [13,14] and 1980 [15-17]. The authors of these works observed that the smallness of the mass of neutrinos can be explained when super-heavy right-handed Majorana neutrinos are introduced, which were considered as the result of grand unification models such as$ SO(10) $ theories or as a consequence of horizontal symmetry. In both cases, the small neutrino mass appears as a consequence of symmetry breaking.Nowadays there is a plethora of seesaw models. With neutrino masses ranging from zero to the GUT scale, mass mechanisms introduce different neutrino states [18]. Apart from Dirac or Majorana types, there are pseudo-Dirac (or quasi-Dirac) [19], schizophrenic [20], or vanilla [21] neutrinos, among others. Popular seesaw mechanisms give a possible dynamical explanation for why known active neutrino states are so light. They appear to be of Majorana type (recently a dynamical explanation for Dirac light neutrinos has been proposed [22]). Seesaw type-I models have been worked out in Refs. [12,14,23,24], type-II in Ref. [25], and type-III in Ref. [26]. A hybrid mechanism is also possible [27]. For the inverse seesaw model, see Refs. [28,29]. Some recent and interesting work on seesaw mechanisms which also touch on cosmological and lepton flavor violation issues can be found in Refs. [30-40].
In the present work, we extend the approach defined in our previous works [41,42], where neutrino mixing matrices were considered from the point of view of matrix analysis, to the case of seesaw scenarios. In Ref. [41] we argued that singular values of mixing matrices and contractions applied to interval mixing matrices determine possible BSM effects in oscillation parameters and can be used to define the physical neutrino mixing space. In addition, a procedure of matrix dilation makes it possible to find BSM extensions based on experimental data given for PMNS mixing matrices. In this way, we are closer to understand a long-standing puzzle in neutrino physics, namely if and what kind of extensions with extra neutrino states are possible, beyond the three known light neutrinos mixing picture. Using these techniques, new stringent limits for the light-heavy neutrino mixings in the 3+1 scenario (three active, light neutrinos plus one extra sterile neutrino state) have been obtained [42].
In what follows, we discuss a second part of the neutrino puzzle, focusing on the neutrino mass matrices and trying to figure out how much information the rigid structure of mass matrices characteristic of seesaw mechanisms provides about the neutrino mass spectrum. In a similar spirit, a perturbation theory was used in Ref. [43] to prove that in the seesaw type I scenario we cannot get the fourth light neutrino. This proof was based on a standard seesaw assumption that elements of the heavy neutrino sector represented conventionally by the Majorana mass matrix
$ M_{R} $ are much larger than elements of the Dirac mass matrix$ M_{D} $ , |mR|$ \gg$ |mD| . Besnard [44] gave an elegant proof, using the min-max theorem, that in the seesaw scenario there is a gap in the spectra. In the proof, the author assumed that the whole mass matrix is not singular and thus excluded a massless neutrino. However, current experimental data do not exclude the possibility of one massless neutrino. Also, the assumption |mR|$ \gg $ |mD| is not sufficient in general. It can be seen in the simplest way by considering$ M_R $ matrix with all elements much larger than those of$ M_D $ , but all equal. In this case, taking, for instance,$ M_R $ three dimensional, the rank of this matrix is 2, so one eigenvalue is zero. This example shows that the relation between matrix structures and derived eigenvalues is complicated. Moreover, considering elements of the same order may be misleading and inaccurate. Even a simple matrix$ A = \left( \begin{array}{cc} 100 & -95 \\ -95 & 90 \end{array} \right) $

(8) results in two completely different scales of eigenvalues
$ \lambda(A) = \lbrace 190.131, -0.131 \rbrace $ . To infer eigenvalues and eigenvectors from the structured, large-dimensional matrices which pose different scales of elements is not trivial. We will examine also a connection between masses and mixings for the generic seesaw model.The structure of the paper is as follows. In the next section we will discuss different ways in which seesaw models can be realized. In Section III the main results are obtained for the neutrino mass spectrum. In a scenario with two sterile neutrinos, analytic entrywise bounds for heavy neutrinos are presented. A higher dimensional situation is discussed using inverse eigenvalue methods for the positive definite matrices only. Also, an alternative proof to Ref. [43] is given, showing that for the seesaw mass matrix with hierarchical block-structured submatrices there are only 3 light neutrino states. In addition, it is shown how large splits among heavy neutrino states can occur. In Section IV we discuss an angle between subspaces of the eigenvalues which connects masses and mixings. In the last section, we conclude our work and present possible directions for further studies of the neutrino mass and mixing matrices. The work is supported by an Appendix where details are given of the matrix theory needed for refining studies of the mass matrix structures.
-
Oscillation experiments have established that neutrinos are not massless [45,46], and we already know that at least two of the three known neutrinos are massive. This calls for the introduction of massive right-handed neutrino states to the matter content of the theory. Then, similarly to the quark sector where right-handed quark fields are present, right-handed neutrino fields
$ \nu_R $ lead to the Dirac mass term in the mass Lagrangian,$ {\cal{L}}_{D} = - \bar{\nu}_{L}M_{D}\nu_{R} + {\rm h.c.}, $

(9) where
$ M_{D} $ is a complex$ 3 \times n_R $ matrix. Now, allowing for self-conjugating Majorana fields$ \nu^{{\cal{C}}} = {\cal{C}}\bar{\nu}^{T} = \nu , $

(10) which relates right-handed and left-handed fermionic fields,
$ \nu_{R} = (\nu_{L})^{{\cal{C}}}, \nu_{L} = (\nu_{R})^{{\cal{C}}} $ , another mass term$ {\cal{L}}_{M} = -\frac{1}{2}\overline{\nu}_{L}M_{L}(\nu_{L})^{{\cal{C}}}+ {\rm h.c.} $

(11) can be constructed.
$ M_{L} $ is a$ 3 \times 3 $ complex symmetric matrix build exclusively from left-handed chiral fields, making a description more economic② [47,48].In the same way
$ M_R $ can be constructed with$ n_R $ right-handed chiral fermionic fields. In general, the mass Lagrangian can include both Dirac and Majorana terms$\begin{aligned}[b] {\cal{L}}_{D+M} = &- \bar{\nu}_{L}M_{D}\nu_{R} -\frac{1}{2} \bar{\nu}_{L}M_{L}(\nu_{L})^{{\cal{C}}} \\&-\frac{1}{2} \overline{(\nu_{R})^{{\cal{C}}}}M_{R}\nu_{R} + {\rm h.c.} . \end{aligned}$

(12) In the Dirac-Majorana mass term the resulting fields are of Majorana type. It is possible to write this in a compact form, in which it resembles the Majorana mass term
$ {\cal{L}}_{D+M} = -\frac{1}{2}\bar{n}_{L}M_{D+M}n_{L}^{{\cal{C}}} + {\rm h.c.}, $

(13) where
$ n_{L} = \left( \nu_{L},(\nu_{R})^{{\cal{C}}}\right)^{T} $ fullfils Eq. (10).The Dirac-Majorana mass term (13) underlies a seesaw mechanism of the neutrino mass generation which tries to explain the small masses of known neutrinos by assuming large masses of sterile neutrinos.
Here we discuss in more detail what has been mentioned in the Introduction. First, we assume that the left-handed Majorana mass term
$ {\cal{L}}_{L} $ vanishes, since it is forbidden by SM symmetries, or it may result from higher-dimensional operators [49], which effectively damp the order of magnitude of$ M_L $ elements below that of$ M_D $ . Secondly, we assume that Dirac neutrinos acquire mass through the standard Higgs mechanism, so the elements of the Dirac neutrino mass matrix are of the order of the electroweak scale. Lastly, perhaps the most important assumption concerns the right-handed Majorana mass term, which is a manifestation of new physics beyond SM, and tells us that right-handed neutrinos are very heavy particles. Altogether, we assume:$ M_{L} \simeq 0, \;M_{D} \sim {\rm EW-}{\rm scale} \ll M_R \sim {\rm GUT-}{\rm scale}, $

(14) where
$ {\rm EW-}{\rm scale} $ refers to the electroweak spontaneous symmetry scale ($ 10^2 $ GeV) and the$ {\rm GUT-}{\rm scale} $ was originally taken to be of the order of$ 10^{15} $ GeV.Hence, we get the
$ 2 \times 2 $ symmetric block seesaw mass matrix as given in Eq. (3), which with assumption (5) gives the neutrino mass spectrum (6) and (7).Kanaya [50] and independently Schechter and Valle [51] showed that it is possible to block diagonalize the seesaw mass matrix, up to the terms of the order
$ M_{R}^{-1}M_{D} $ . In this case the mixing matrix takes the following form:$ \left( \begin{array}{ll} 1 - \dfrac{1}{2}M_{D}^\dagger (M_{R}M_{R}^\dagger )^{-1}M_{D} & (M_{R}^{-1}M_{D})^\dagger \\ -M_{R}^{-1}M_{D} & 1 -\dfrac{1}{2}M_{R}^{-1}M_{D}M_{D}^\dagger (M_{R}^\dagger )^{-1} \end{array} \right). $

(15) The seesaw mechanism can be neatly connected with the effective theory [49] in which
$ {\cal{L}}_{\rm eff} = - \frac{1}{\Lambda} \sum_{l',l} y_{l'l}(\Psi_{l'L}^{T}\sigma_{2} \Phi){\cal{C}}^{-1}(\Phi^{T} \sigma_{2} \Psi_{lL}) + {\rm h.c.}, $

(16) and
$ \psi_{lL}^T = \left( \nu_{lL}, l_{L} \right), \Phi^T = \left( \Phi^{+}, \Phi^{0} \right) $ are the SM lepton and Higgs doublets, respectively. The coefficients$ y_{l' l} $ denote dimensionless couplings and$ \Lambda $ is the energy scale at which new physics effects do not decouple. After spontaneous electroweak symmetry breaking,${\cal{L}}_{\rm eff}$ takes the form$ {\cal{L}}_{\rm eff} \to {\cal{L}}_{L} = -\frac{1}{2} \bar{\nu}_{L}{\cal{M}}_{L}(\nu_{L})^{{\cal{C}}} + {\rm h.c.} $

(17) with
$ {\cal{M}}_{L} = \frac{y {v^{2}}}{\Lambda}. $

(18) There exist many ways to extend the SM which result in the effective Lagrangian (16). On the other hand, if we assume that we complete the SM by adding only one type of particle, we are constrained to three possibilities to induce a light neutrino spectrum. These three possibilities lead to the different realizations of the seesaw mechanism:
1. Seesaw Type-I (canonical seesaw).
In this case, we add right-handed neutrino fields
$ \nu_{R} $ to the SM. Thus, we get the seesaw formula discussed previously$ \begin{aligned}[b]& {\cal{M}}_{L}\to M_{\rm light} \simeq -M_{D}^{T}M_{R}^{-1}M_{D}, \\& \vert { {m}}_{D} \vert \ll \vert { m}_{R} \vert. \end{aligned}$

(19) Here
$ \Lambda $ in Eq. (16) is identified with the inverse of matrix$ M_R $ .Instead of
$ \nu_{R} $ we can add a scalar boson triplet$ \Delta = (\Delta^{++}, \Delta^{+}, \Delta^{0}) $ to get small neutrino masses. Here$ \Lambda $ in Eq. (16) is identified with the masses of scalar boson triplets. In this variation of the seesaw model, the masses of the neutrinos are given by$ {\cal{M}}_{L}\to M_{\rm light} \simeq \frac{\mu {v^{2}}}{M_{\Delta}^{2}}, \quad \vert \mu \vert \sim \vert m_{\Delta} \vert, \ \vert v \vert \ll \vert m_{\Delta} \vert, $

(20) where
$ M_{\Delta} $ corresponds to the mass of the boson triplet$ \Delta $ .3. Seesaw Type-III [26].
In the last case we complement SM with a fermion triplet
$ \Sigma = ( \Sigma^{+}, \Sigma^{0}, \Sigma^{-}) $ which corresponds to$ \Lambda $ in Eq. (16). In the Type-III mechanism we get the following formula for neutrinos masses:$ {\cal{M}}_{L}\to M_{\rm light} \simeq -y^{T}M_{\Sigma}^{-1}y v^{2}, \quad \vert y \vert \ll \vert m_{\Sigma} \vert, $

(21) where
$ M_{\Sigma} $ corresponds to the mass of the fermion triplet$ \Sigma $ . -
Now we focus on seesaw extensions connected with extra fermion fields, which is a wide area of studies. In most of them, besides the right-handed neutrino fields
$ \nu_{R} $ characteristic for the seesaw type-I model, new singlet fermion fields$ S_{R} $ are added. This type of extension of the seesaw mechanism was introduced for the first time in 1983 by Wyler and Wolfenstein [52]. The corresponding general mass term takes the following form:$ \begin{aligned}[b] {\cal{L}}_{\rm ESS} =& - \bar{\nu}_{L}M_{D}\nu_{R} - \bar{\nu}_{L}M_{L}(\nu_{L})^{{\cal{C}}} - \overline{(\nu_{R})^{{\cal{C}}}}M_{R}\nu_{R} \\ &- \bar{\nu}_{L}M_{1} S_{R} - \overline{(\nu_{R})^{{\cal{C}}}}M_{2}S_{R} \\&- \overline{(S_{R})^{{\cal{C}}}}M_{3} S_{R} + {\rm h.c.}, \end{aligned} $

(22) where
$ M_{D} $ ,$ M_{1} $ ,$ M_{2} $ are matrices of the Dirac type and$ M_{L} $ ,$ M_{R} $ ,$ M_{3} $ are matrices of the Majorana type. This mass term can be written in a compact form, in a similar way as for an ordinary seesaw:$ {\cal{L}}_{\rm ESS} = -\bar{N}_{L}M_{\rm ESS}N_{L}^{{\cal{C}}} + {\rm h.c.} $

(23) with the symmetric mass matrix
$M_{\rm ESS}$ $ M_{\rm ESS} = \left( \begin{array}{ccc} M_{L} & M_{D} & M_{1} \\ M_{D}^{T} & M_{R} & M_{2} \\ M_{1}^{T} & M_{2}^{T} & M_{3} \end{array} \right). $

(24) However, the most popular extensions of the seesaw mechanism with additional singlet fields, namely an inverse seesaw (ISS) and a linear seesaw (LSS), use a less general structure of
$M_{\rm ESS}$ $ \begin{array}{l} {M_{\rm ISS}} \!=\! \left( {\begin{array}{*{20}{c}} 0&{{M_D}}&0\\ {M_D^T}&0&{{M_2}}\\ 0&{M_2^T}&{{M_3}} \end{array}} \right),\;\;\;\;\;{M_{\rm LSS}}\! =\! \left( {\begin{array}{*{20}{c}} 0&{{M_D}}&{{M_1}}\\ {M_D^T}&0&{{M_2}}\\ {M_1^T}&{M_2^T}&0 \end{array}} \right)\\ {\rm{ where }}:\quad \left| {{m_3}} \right| \ll \left| {{m_D}} \right| \ll \left| {{m_2}} \right|,\;\;\;\;\;\;\;\;\;\;\;\;\;\;\left| {{m_D}} \right|\sim \left| {{m_1}} \right| \ll \left| {{m_2}} \right|. \end{array}$

(25) It is important that for both linear and inverse seesaw mechanisms, we can rearrange the mass matrices in such a way that they will have the same structure as Eq. (3):
$ \begin{aligned}[b]& {\rm ISS}: \\& {\cal{M}}_{D} = \left( M_{D}, 0 \right), \quad {\cal{M}}_{R} = \left( \begin{array}{cc} 0 & M_{2} \\ M_{2}^{T} & M_{3} \end{array} \right), \end{aligned} $

(26) $ \begin{aligned}[b]& {\rm LSS}: \\&{\cal{M}}_{D} = \left( M_{D}, M_{1} \right), \quad {\cal{M}}_{R} = \left( \begin{array}{cc} 0 & M_{2} \\ M_{2}^{T} & 0 \end{array} \right). \end{aligned} $

(27) Due to this rearrangement, these models can be analysed in the same way as the canonical seesaw (3), with the same hierarchy of elements, i.e. |
D|
$ \ll $ |Using Eqs. (4) and (15), we get the following formula for the light neutrino sector in the
${\rm ISS}$ case:$ M_{\rm light} = M_{D}M_{2}^{-1}M_{3}(M_{2}^{-1})^{T}M_{D}^{T}. $

(28) In the inverse seesaw scenario, a small neutrino mass is obtained by double suppression of the Dirac mass matrix. It is first suppressed by the matrix
$ M_{3} $ , and the second source of suppression lies in the inverse of the matrix$ M_{2} $ , which has elements much larger than those of$ M_{D} $ . It implies that the order of magnitude of elements of$ M_{2} $ can be smaller than the corresponding elements of$ M_{R} $ in the canonical seesaw. Thus, it is more plausible to detect such heavy neutrino states in high energy colliders.Similarly, in the
${\rm LSS}$ case the light neutrino sector is given by the formula$ M_{\rm light} = - M_{D}M_{2}^{-1}M_{1} - M_{1}^{T}(M_{2}^{-1})^{T}M_{D}^{T} . $

(29) Here, the light neutrino sector depends linearly on the Dirac mass matrix
$ M_{D} $ , in contrast to quadratic dependence in the ordinary seesaw mechanism.We can see that despite differences in the structure of linear, inverse and type-I seesaw scenarios, the corresponding mass matrices can be expressed uniformly by one general matrix,
$ {\cal{M}} = \left( \begin{array}{cc} 0 & {\cal{M}}_{D} \\ {\cal{M}}_{D}^{T} & {\cal{M}}_{R} \end{array} \right), $

(30) with
The structure of the seesaw mass matrix (30) with the assumption (31) is the starting point for analysis of the general properties of the eigenvalues and eigenvectors which arise.
-
The matrix
$ {\cal{M}} $ in Eq. (30) can be split into the sum of two matrices with different scales of elements:$ \begin{aligned}[b] {\cal M} = &\left( {\begin{array}{*{20}{c}} 0&{{{\cal M}_D}}\\ {{\cal M}_D^T}&{{{\cal M}_R}} \end{array}} \right) = \left( {\begin{array}{*{20}{c}} 0&0\\ 0&{{{\cal M}_R}} \end{array}} \right) + \left( {\begin{array}{*{20}{c}} 0&{{{\cal M}_D}}\\ {{\cal M}_D^T}&0 \end{array}} \right)\\ \equiv & {\hat{{\cal{M}}}_R} + {\hat{{\cal{M}}}_D}. \end{aligned}$

(32) Such a split gives us an opportunity to use the theorem from the matrix analysis (Theorem B7) (eigenvalues and singular values of a given matrix M will be denoted by
$ \lambda_{i}(M) $ and$ \sigma_{i}(M) $ $ i = 1,2,\cdots,n $ , respectively; see Appendix A for relevant definitions), which connects the spectrum of the sum of two matrices with the spectrum of those matrices. However, this is true only for Hermitian matrices. Therefore, at the beginning we will consider a real symmetric mass matrix which implies the conservation of CP symmetry, see e.g. Refs. [53-58]. In what follows, the CP invariance will be identified with a real symmetric mass matrix. With these assumptions, we get the following result.Proposition III.1. In the CP-invariant seesaw scenario with
$\lambda({\cal{M}}_{R}) \gg$ |$ {\cal{M}}_{D} \in M_{3 \times n}, {\cal{M}}_{R} \in M_{n \times n} $ , exactly 3 light neutrinos are present.Proof. In the seesaw model, we assume two well-separated scales of elements of the mass matrix (31). Let us split the mass matrix
$ {\cal{M}} $ according to these scales into the sum (32). Weyl's inequalities (B4) can be transformed into the following inequality:$ \vert \lambda_{i}({\cal{M}})- \lambda_{i}(\hat{{\cal{M}}}_{R}) \vert \leqslant \rho(\hat{{\cal{M}}}_{D}). $

(33) The spectral radius is smaller than each matrix norm (B1), and in particular,
$ \begin{array}{l} \rho(\hat{{\cal{M}}}_{D}) \leqslant \Vert \hat{{\cal{M}}}_{D} \Vert_{2} = \Vert {\cal{M}}_{D} \Vert_{2} \leqslant \Vert {\cal{M}}_{D} \Vert_{F}, \end{array} $

(34) where
$ \Vert \ast \Vert_{2} $ is an operator norm. We use the fact that the operator norms of$ \hat{{\cal{M}}}_{D} $ and$ {\cal{M}}_{D} $ are equal and also the following relation between the operator and Forbenius norm:$ \Vert \ast \Vert_{2} \leqslant \Vert \ast \Vert_{F} $ . Since all elements of$ {\cal{M}}_{D} $ have the same order of magnitude, the following estimation can be madeOn the other hand, we know that matrix
$ \hat{{\cal{M}}}_{R} $ has at least three eigenvalues equal to 0. Since the eigenvalues of the Hermitian matrix can be arranged as in Eq. (B2), we have$ \vert \lambda_{i}({\cal{M}})- 0 \vert \leqslant \rho(\hat{{\cal{M}}}_{D}) \quad {\rm for} \quad \lambda_{i}(\hat{{\cal{M}}}_{R}) = 0. $

(36) Hence, three eigenvalues of
$ {\cal{M}} $ must be smaller than$\sqrt{3n}$ |Now, let us assume that
$\vert \lambda({\cal{M}}_{R}) \vert \gg $ |$ {\cal{M}} $ must be large, i.e. of the order of elements of$ {\cal{M}}_{R} $ . This is another conclusion from Weyl's inequalities. Equation (33) tells us that the eigenvalues of$ {\cal{M}} $ are maximally shifted by |$ \hat{{\cal{M}}}_{R} $ . However, all eigenvalues of$ \hat{{\cal{M}}}_{R} $ which remain are equal to eigenvalues of$ {\cal{M}}_{R} $ . Therefore,Thus, in the CP-invariant seesaw scenario with
$\vert \lambda({\cal{M}}_{R}) \vert \gg $ |As the matrix
$ {\cal{M}}_D $ couples left-handed and right-handed chiral fermions, Eq. (37) estimates the mass of heavy neutrinos to be the mass obtained by neglecting light neutrinos, shifted at most by the maximal strength of the coupling to the light neutrino sector.The above discussion relies on the eigenvalues of mass matrices. However, eigenvalues are not good quantities for general neutrino mass scenarios with complex symmetric matrices. Such matrices can have complex eigenvalues, and moreover, they are not always diagonalizable by the unitary similarity transformation. Instead, singular values are useful, since due to the Autonne-Takagi theorem (Theorem B5), we can always find a unitary transformation which will diagonalize the complex seesaw mass matrix. Thus, the above result can be generalized to the complex seesaw scenario with the use of the analog of Weyl's inequalities for singular values.
Corollary 1. In the seesaw scenario with
$\sigma({\cal{M}}_{R}) \gg $ |$ {\cal{M}}_{D} \in M_{3 \times n}, {\cal{M}}_{R} \in M_{n \times n} $ , exactly 3 light neutrinos are present.Proof. For singular values, we have the analog of Weyl's inequalities,
$ \vert \sigma_{i}({\cal{M}}) -\sigma_{i}(\hat{{\cal{M}}}_{R})\vert \leqslant \sigma_{1}(\hat{{\cal{M}}}_{D}) = \Vert \hat{{\cal{M}}}_{D} \Vert_{2}, $

(38) thus using similar arguments as in the proof of Proposition III.1, we attain the assertion.
One of the main seesaw mechanism assumptions is that besides the three light neutrinos, all additional neutrinos should be very massive. The masses of heavy neutrinos are dominated by the spectrum of the
$ {\cal{M}}_{R} $ submatrix. However, as we can see from the simple example (8), even when the elements of the matrix are of the same order, the eigenvalues can fall apart. As a consequence, some eigenvalues of$M_{\rm heavy}$ could be very small, which contradicts the seesaw assumptions. Such a possibility can easily be seen from the Laguerre–Samuelson inequality for the real roots of polynomials. Our goal is to establish conditions under which eigenvalues of the$ {\cal{M}}_{R} $ matrix are always large. In the case of one additional neutrino, the situation is trivial since$ {\cal{M}}_{R} $ is represented by just one number. Moreover, in this case, the seesaw mechanism is no longer valid, since the light spectrum contains two massless neutrinos, which contradicts experimental results. With two and more additional neutrinos the general solution to the problem is very difficult. In principle, we want to exclude the region smaller than some boundary value. In general, the$ {\cal{M}} $ matrix is complex symmetric and masses correspond to the singular values. Thus, if we are able to find a lower bound for the smallest singular value and impose it to be larger than some limit value, the problem is solved. Moreover, in the CP-invariant scenario,$ {\cal{M}} $ can be considered as real and symmetric, in which case the masses are given by eigenvalues. It is known that for normal matrices singular values are equal to the absolute values of the eigenvalues [59]. Thus, by bounding singular values we treat both cases. In the mathematical literature, there are available different lower bounds for the smallest singular value expressed by matrix elements [60-65]. We follow Refs. [61,64], where$ \sigma_{n}(A) \geqslant \vert {\rm det}\, A \vert \left( \frac{n-1}{\Vert A \Vert_{F}^{2}} \right)^{\textstyle\frac{n-1}{2}} \geqslant X, $

(39) and n is the dimension of the matrix. X is some boundary value and A is a matrix with elements
$ a_{11},a_{12},...,a_{nn} $ . This nontrivial inequality can be solved analytically in two dimensions, corresponding to the scenario with two additional neutrinos, using e.g. Mathematica [66]. This scenario, known as the minimal seesaw, is currently being studied intensively [67-73]. The analytic formulas restrict matrix elements to singular values larger than some positive number X, which in the case of eigenvalues correspond to the region outside the interval$ (-X,X) $ . Using the abbreviations:$ \begin{aligned}[b] Y_1 = \frac{a_{11} a_{12}^2}{a_{11}^2-X^2}, \quad Y_2 = \sqrt{\frac{a_{11}^4 X^2+2 a_{11}^2 a_{12}^2 X^2-a_{11}^2 X^4+a_{12}^4 X^2-2 a_{12}^2 X^4}{\left(a_{11}^2-X^2\right)^2}}, \end{aligned} $

(40) $ \begin{aligned}[b] Y_3 = \frac{-a_{11}^2 X^2+a_{12}^4-2 a_{12}^2 X^2}{2 a_{11} a_{12}^2},\quad Y_4 = \sqrt{\sqrt{X^4-a_{11}^2 X^2}-a_{11}^2+X^2}, \end{aligned} $

(41) we get:
$ \begin{aligned}[b] a_{12},a_{22} \in \mathbb{R} \land & \Bigg\{ \bigg( a_{11}>X\land X>0\land a_{22}\geqslant Y_1+Y_2\bigg)\lor \bigg( a_{11}>X\land X>0\land a_{22}\leqslant Y_1-Y_2\bigg)\lor \\ &\bigg( X>0\land a_{22}\geqslant Y_1+Y_2\land a_{11}<-X\bigg)\lor \bigg(X>0\land a_{11}<-X\land a_{22}\leqslant Y_1-Y_2\bigg)\lor \\ &\bigg( -X = a_{11}\land a_{12}>0\land X>0\land a_{22}\geqslant Y_3 \bigg)\lor \bigg( -X = a_{11}\land X>0\land a_{22}\geqslant Y_3 \land a_{12}<0\bigg)\lor \\ &\bigg( X = a_{11}\land a_{12}>0\land X>0\land a_{22}\leqslant Y_3 \bigg)\lor \bigg( X = a_{11}\land X>0\land a_{12}<0\land a_{22}\leqslant Y_3 \bigg)\lor \\ &\bigg(-Y_4 = a_{12}\land Y_1-Y_2 = a_{22}\land X>0\land a_{11}<X\land -X<a_{11} \bigg)\lor \\ &\bigg( Y_4 = a_{12}\land Y_1-Y_2 = a_{22}\land X>0\land a_{11}<X\land -X<a_{11} \bigg)\lor \\ &\bigg( a_{12}>Y_4\land X>0\land a_{11}<X\land -X<a_{11}\land a_{22}\leqslant Y_1+Y_2\land Y_1-Y_2\leqslant a_{22}\bigg)\lor \\ &\bigg( X>0\land a_{11}<X\land a_{12}<-Y_4\land -X<a_{11}\land a_{22}\leqslant Y_1+Y_2\land Y_1-Y_2\leqslant a_{22}\bigg) \bigg\}. \end{aligned} $

(42) To approach higher-dimensional cases we use the inverse eigenvalue problem, i.e. reconstruction of matrices from the spectrum [74,75]. Such a reconstruction for Hermitian matrices, i.e. in the CP-invariant scenario, is controlled by the Schur-Horn theorem [76,77]
Theorem III.1. (Schur-Horn) Let
$ \lbrace \lambda_{i} \rbrace_{i = 1}^{n} $ and$ \lbrace d_{i} \rbrace_{i = 1}^{n} $ be vectors in$ \mathbb{R}^{n} $ with entries in non-increasing order. There is a Hermitian matrix with diagonal entries$ \lbrace d_{i} \rbrace_{i = 1}^{n} $ and eigenvalues$ \lbrace \lambda_{i} \rbrace_{i = 1}^{n} $ if and only if$ \sum\limits_{i = 1}^{k} d_{i} \leqslant \sum\limits_{i = 1}^{k} \lambda_{i} \quad k = 1,\cdots,n \;\; {{and}}\;\; \sum\limits_{i = 1}^{n} d_{i} = \sum\limits_{i = 1}^{n} \lambda_{i}. $

(43) The construction of matrices based on this theorem can be realized by different approaches [78-82]. An important feature of this theorem is the majorization condition between eigenvalues and diagonal elements (43). In the case of large eigenvalues, this relation implies that diagonal elements must also be large in comparison to off-diagonal elements. However, this works only if the
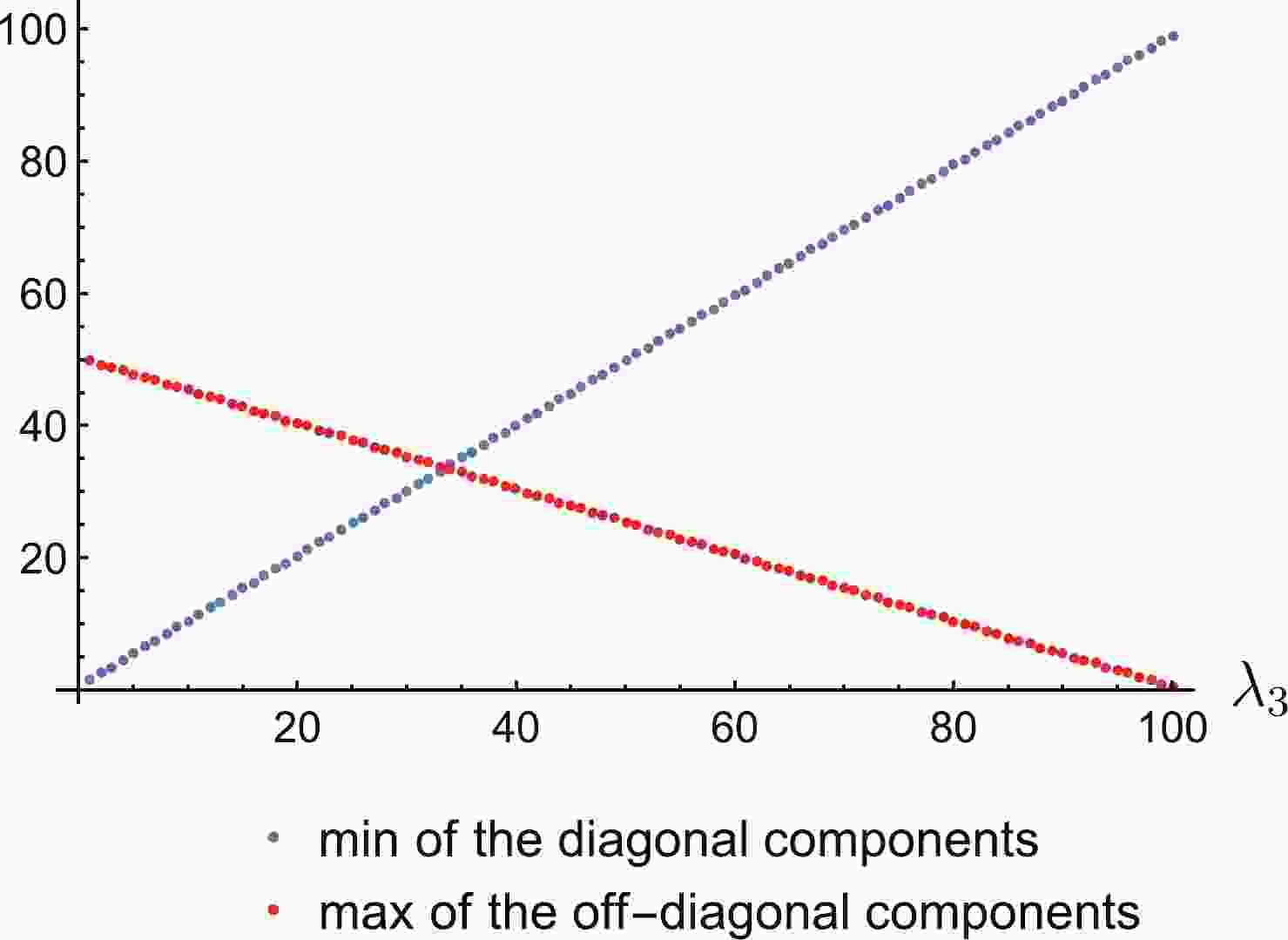
$ {\cal{M}}_{R} $ matrix is non-negative definite, i.e. all eigenvalues are non-negative. Such a situation in the case of three sterile neutrinos is presented in Fig. 1. In a scenario with some eigenvalues large but negative, Eq. (43) does not restrict matrix elements.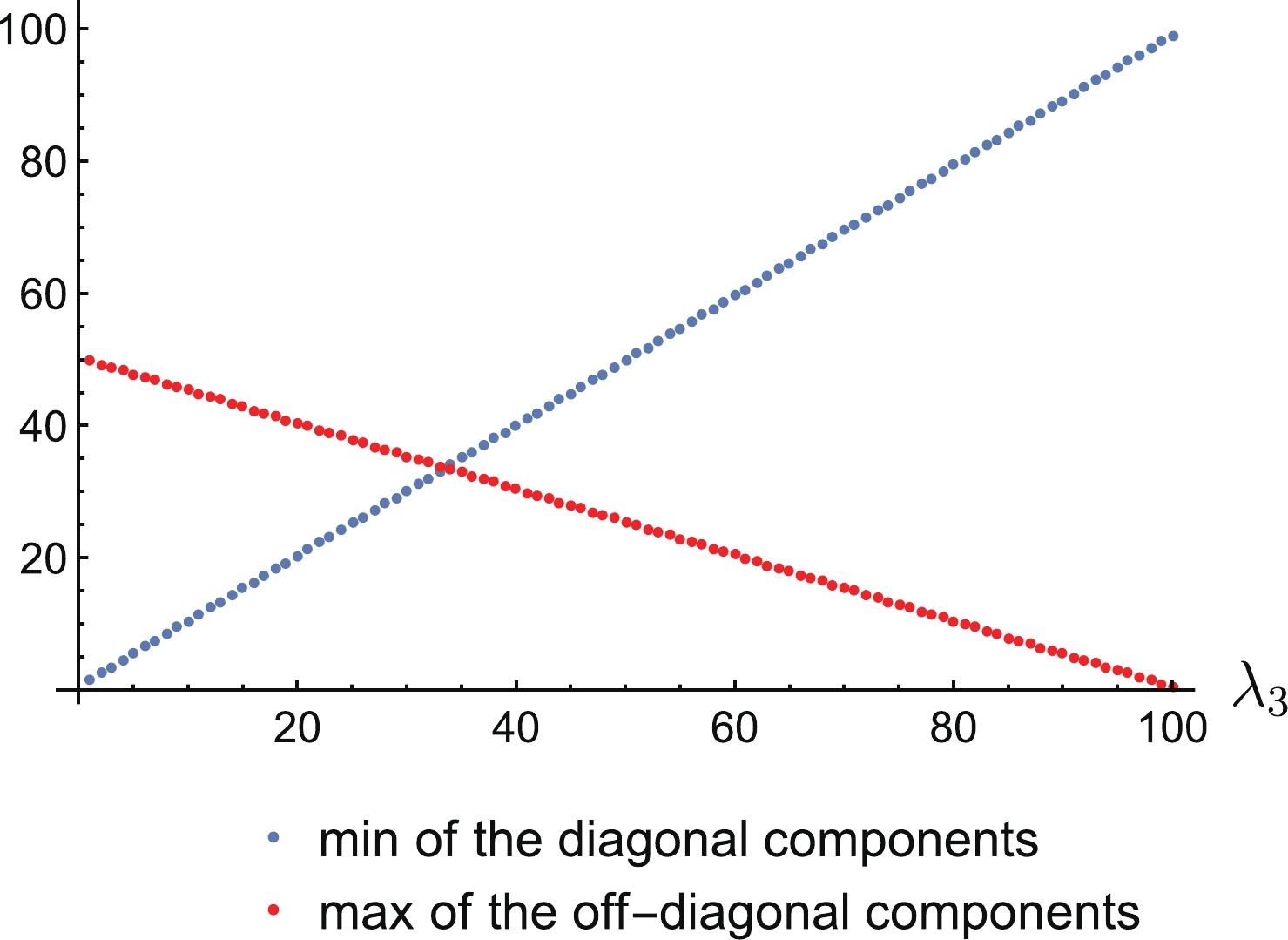
Figure 1. (color online) An illustration of the Schur-Horn theorem for the non-negative definite matrix. Two eigenvalues have been set up to
$\lambda_{1}=101$ and$\lambda_{2}=100 $ , and the third eigenvalue$\lambda_{3}$ ranges from 0 to 100 to see the behavior of the diagonal elements and off-diagonal elements for a different spread between eigenvalues. When the spread is large, i.e.$\lambda_{3} \sim 0$ , the diagonal elements can be very small and off-diagonal elements can take significant values. On the other hand, if all eigenvalues are large then diagonal elements dominate.To bypass the requirement of non-negative definiteness and CP conservation, we can invoke singular values once again. As in the eigenvalue case, singular values can also be used to reconstruct a matrix via a procedure known as the inverse singular value problem [83,84]. However, we currently have at our disposal only theorems which connect eigenvalues and singular values (Weyl-Horn theorem [85,86]) or singular values and diagonal elements (Sing-Thompson theorem [87,88]). Thus, we miss the symmetry of the matrix and further work is needed to combine all these components.
-
We are interested in how masses and mixings are connected to each other in the seesaw scenario. Recently, an interesting relation has been found between eigenvectors and eigenvalues for neutrino oscillations in [89, 90]. To answer this we will study the behavior of the eigenspace of the matrix
$ \hat{{\cal{M}}}_{R} $ under the perturbation$ \hat{{\cal{M}}}_{D} $ (32). Thus, we are interested in the estimation of the difference between eigenspaces spanned by eigenvectors of$ \hat{{\cal{M}}}_{R} $ and$ {\cal{M}} $ (32). As a starting point, let us consider the eigenproblem for the matrix$ \hat{{\cal{M}}}_{R} $ . For block-diagonal matrices, eigenvalues correspond to the eigenvalues of its diagonal blocks. In this case, one of these blocks is a zero matrix. Thus, this block has a threefold eigenvalue 0 and the corresponding eigenvectors are$ \begin{aligned}[b]& (1,0,0,0,0,0,\cdots,0)^{T},\\& (0,1,0,0,0,0,\cdots,0)^{T}, \\ & (0,0,1,0,0,0,\cdots,0)^{T}. \end{aligned} $

(44) They span a standard 3-dimensional Euclidean space embedded in a (3+n)-dimensional space. The rest of the eigenvalues of
$ \hat{{\cal{M}}}_{R} $ correspond to those of the$ {\cal{M}}_{R} $ submatrix. Our approach will be based on the Davis-Kahan theorem (TheoremC2), which is valid for the CP-conserving case (a generalization to the CP-violating case seems to be possible [91], but it requires a separate study). It allows us to estimate the sine of the angle between subspaces, denoted as$ \sin\Theta $ , spanned by the eigenvectors. Since the eigenspace spanned by the zero eigenvalues of$ \hat{{\cal{M}}}_{R} $ has a very simple structure, we will focus on the estimation of the angle between spaces corresponding to light neutrinos. Information about the other pair of subspaces follows immediately from the orthogonality of the mixing matrix. Let us denote the eigenspaces spanned by the eigenvectors corresponding to small eigenvalues by$ V_{L} $ and$ V_{L}^{'} $ , respectively for$ \hat{{\cal{M}}}_{R} $ and$ {\cal{M}} $ . Then in the seesaw scenario (see Fig. 2) we have
Figure 2. (color online) The behavior of the
$\sin \Theta$ , controlled by the Davis-Kahan theorem, in the seesaw scenario. The region below the graph represents allowed values. In this case,$\sin \Theta$ is bounded by a function depending on the norm of${\cal{M}}_{D}$ and the gap between the spectrum. As heavy neutrinos become lighter and lighter the blowout of the bound is observed.$ \Vert \sin\Theta(V_{L},V_{L}^{'}) \Vert \leqslant \frac{1}{\delta} \Vert {\cal{M}} - \hat{{\cal{M}}}_{R} \Vert = \frac{1}{\delta} \Vert {\cal{M}}_{D} \Vert, $

(45) where
$ \delta $ is the distance between the largest of the light masses and the smallest of the heavy masses. The above inequality says that$ \sin\Theta(V_{L},V_{L}^{'}) $ can be estimated using a gap between the spectra and the size of the perturbation. It is clear that if the subspaces$ V_{L} $ and$ V_{L}^{'} $ are close to each other then the sine between them will tend to zero. Therefore, from (45) we can draw the following conclusions:● If the separation between light and heavy neutrinos is pronounced, as in the seesaw case, then the subspace spanned by light neutrinos is almost parallel to the 3-dimensional Euclidean space. However, when these two spectra approach each other not much information can be retrieved from Theorem C2.
● Even if the
$ \delta $ is not that large, these two subspaces still can be almost parallel when$ {\cal{M}}_{D} $ is very small. -
Simple ideas are very often the most powerful, and this is the case for the seesaw mechanism, which provides an attractive way to explain the smallness of the light neutrino masses by introducing very massive sterile neutrino states. This manifests in a specific structure of the mass and mixing matrices. We treat various seesaw types of mass matrices uniformly, including linear and inverse extensions, using the same, general and rigid-block mass matrix structure. We have proved that under the general sub-matrix mass hierarchies (31) exactly three light neutrinos emerge (Prop. III.1 and Cor. 1). Moreover, as a consequence we have derived the allowed splitting for heavy neutrinos in terms of submatrices
$ {\cal{M}}_{D} $ and$ {\cal{M}}_{R} $ (37). As the spectrum of$ {\cal{M}}_{R} $ dominates the contribution to heavy masses, we have investigated the structure of this matrix to ensure the spectrum is large. In a minimal seesaw scenario with two sterile neutrinos, we have given analytic bounds for heavy neutrino masses expressed by the matrix elements (42). For cases with a larger number of additional neutrinos the inverse eigenvalue problem has been applied. However this can be done systematically only in the CP-invariant case and for positive definite matrices. The general solution for any dimension still requires more study. The inverse singular value methods could be especially useful. This requires connection of currently available theorems with the specific structure of the seesaw mass matrix. Lastly, we studied the behavior of the angle between subspaces spanned by the eigenvectors which connects masses with mixings. In this case the Davis-Kahan theorem applied to the seesaw mechanism gives a simple estimation of the angle between mixing spaces depending on the norm of the Dirac mass matrix.Our work is based on matrix theory, which is a vast and rich field. We would like to outline a few potential directions related to neutrino physics for further studies:
● Gershgorin circles provide alternative inclusive entrywise bounds for eigenvalues. They can be applied to models with a diagonally dominant mass matrix to get insight into the mass spectrum.
● Symmetric gauge functions are strictly connected to the unitary invariant norms. We use unitary invariant norms in our study of the mixing matrices [41,42,92]. The symmetric gauge functions can provide a new perspective into the mixing analysis.
● The characteristic polynomial with real roots discussed in this work is a particular example of hyperbolic polynomials. This gives the opportunity to study eigenvalue problems from a more general point of view.
● Semidefinite programming (SDP) does not come directly from matrix theory. However, this area of mathematical programming is based on positive-definite matrices. SDP can be used to better understand the region of physically admissible mixing matrices [41,93].
-
We would like to thank Krzysztof Bielas and Marek Gluza for useful remarks.
-
In this appendix we introduce definitions and theorems used in the main text. Proofs for statements presented here can be found in Refs. [94-96].
-
Let us begin with consideration the matrix "size" problem. A set of all matrices of a given dimension along with matrix addition and matrix multiplication creates a vector space. Thus, it is natural to consider a size of vectors or a distance between two points of this space. This can be done by introducing a function called the norm.
Definition 1 A norm for a real or complex vector space V is a function
$ \Vert \cdot \Vert $ mapping V into$ \mathbb{R} $ that satisfies the following conditions:$ \tag{A1} \begin{aligned}[b] & \Vert A \Vert \geqslant 0 \ {\rm and} \ \Vert A \Vert = 0 \Leftrightarrow A = 0, \\& \Vert \alpha A \Vert = \vert \alpha\, \vert \Vert A \Vert, \\& \Vert A+B \Vert \leqslant \Vert A \Vert + \Vert B \Vert. \end{aligned} $

The same is true for the matrix space. However, for matrices, this can be done in two ways. We can use either the standard vector norm (A1) or introduce the more adequate so-called matrix norm which takes into account specific matrix multiplication.
Definition 2 A matrix norm is a function
$ \Vert \cdot \Vert $ from the set of all complex matrices into$ \mathbb{R} $ that satisfies the following properties$ \tag{A2} \begin{aligned}[b] &\Vert A \Vert \geqslant 0 \ {\rm and} \ \Vert A \Vert = 0 \Leftrightarrow A = 0, \\& \Vert \alpha A \Vert = \vert \alpha \vert\, \Vert A \Vert, \\ &\Vert A+B \Vert \leqslant \Vert A \Vert + \Vert B \Vert, \\& \Vert A B \Vert \leqslant \Vert A \Vert\, \Vert B \Vert. \end{aligned} $

It is important to emphasize that usual vector norms (A1) and matrix norms (A2) are strictly connected: Any vector norm can be translated into a matrix norm in the following way
$\tag{A3} \Vert A \Vert_{\star} = \max_{\Vert x \Vert_{\star} = 1}\Vert Ax \Vert_{\star}, $

where
$ \Vert \cdot \Vert_{\star} $ stands for a corresponding vector norm. The matrix norm defined in this way ensures the submultiplicativity condition and is called the induced matrix norm. The most popular matrix norms are:● Spectral norm:
$ \Vert A \Vert = \max_{\Vert x \Vert_{2} = 1} \Vert Ax \Vert_{2} = \sigma_{1}(A) $ .● Frobenius norm:
$\Vert A \Vert_{F} = \sqrt{{\rm Tr}(A^\dagger A)} = \sqrt{\displaystyle\sum_{i,j = 1}^{n}\vert a_{ij} \vert^{2}} = \sqrt{\displaystyle\sum_{i = 1}^{n}\sigma_{i}^{2}(A)}$ .● Maximum absolute column sum norm:
$ \Vert A \Vert_{1} = \max_{\Vert x \Vert_{1} = 1} \Vert Ax \Vert_{1} = \max_{j} \displaystyle\sum_{i}\vert a_{ij} \vert $ .● Maximum absolute row sum norm:
$ \Vert A \Vert_{\infty} = \max_{\Vert x \Vert_{\infty} = 1} \Vert Ax \Vert_{\infty} = \max_{i} \displaystyle\sum_{j}\vert a_{ij} \vert $ . -
Neutrinos with definite masses are obtained through a unitary transformation which brings the mass matrix into diagonal form. In a general seesaw scenario where diagonalization is done by the congruence transformation (4), masses are given by singular values. However, if we restrict attention to the CP-invariant case, diagonalization goes through the similarity transformation, and the quantities corresponding to neutrino masses are eigenvalues. We will present a theorem concerning both of these quantities, starting with the notion of a spectral radius.
Definition 3. Let
$ A \in M_{n} $ . The spectral radius of A is$ \rho(A) = \max \lbrace \vert \lambda \vert : \ \lambda \in \sigma(A) \rbrace $ .All matrix norms and the spectral radius are connected by the following theorem.
Theorem B1. Let A be an
$ n \times n $ matrix, then for any matrix norm$ \Vert \cdot \Vert $ the following statement is true:$ \tag{B1} \rho(A)\leqslant \Vert A \Vert. $

Theorem B2. Let
$ A \in M_{n} $ be Hermitian. Then the eigenvalues of A are real.Using this theorem we can arrange the eigenvalues of a given Hermitian matrix
$ A \in M_{n} $ , e.g, in a decreasing order$\tag{B2} \lambda_{1} \geqslant \cdots \geqslant \lambda_{n}, $

and this convention is used in this work.
Theorem B3. (Spectral theorem for Hermitian matri-ces)
A matrix
$ A \in M_{n} $ is Hermitian if and only if there is a unitary$ U \in M_{n} $ and diagonal$ \Lambda \in M_{n} $ such that$ A = U \Lambda U^\dagger $ .There exists an equivalent decomposition theorem for singular values.
Theorem B4. (Singular value decomposition)
Let
$ A\in M_{m \times n} $ be given and let$ q = \min \lbrace m,n \rbrace $ . Then there is a matrix$ \Sigma = (\sigma_{ij}) \in M_{m \times n} $ with$ \sigma_{ij} = 0 $ for all$ i \neq j $ and$ \sigma_{11}\geqslant \sigma_{22} \geqslant \cdots \geqslant \sigma_{qq} $ , and there are two unitary matrices$ V \in M_{m \times m} $ and$ U \in M_{n \times n} $ such that$ A = V \Sigma U^\dagger $ .Autonne and Takagi [97,98] gave us a criterion based on singular values, which characterizes the class of symmetric matrices.
Theorem B5. (Autonne-Takagi)
Let
$ A \in M_{n} $ . Then$ A = A^{T} $ if and only if there is a unitary matrix$ U \in M_{n} $ and a nonnegative diagonal matrix$ \Sigma $ such that$ A = U \Sigma U^{T} $ . The diagonal entries of$ \Sigma $ are the singular values of A.Since there are matrices for which both sets of eigenvalues and of singular values are well defined, the question naturally arises of how these quantities are connected. The following theorem provides the basic relation between these numbers.
Theorem B6. Let
$ A \in M_{n} $ have singular values$ \sigma_{1}(A) \geqslant \cdots \geqslant \sigma_{n}(A) \geqslant 0 $ and eigenvalues$ \lbrace \lambda_{1}(A), \cdots, \lambda_{n}(A) \rbrace \in \mathbb{C} $ ordered so that$ \vert \lambda_{1}(A) \vert \geqslant \cdots \geqslant \vert \lambda_{n}(A) \vert $ . Then$\tag{B3} \begin{aligned}[b]& \vert \lambda_{1}(A)\cdots\lambda_{k}(A) \vert \leqslant \sigma_{1}(A)\cdots\sigma_{k}(A)\; {for}\; k = 1,\cdots,n \end{aligned} $

with equality for k = n.
Using the above definitions and basic theorems, a theorem which bounds eigenvalues of the sum of two matrices can be formulated. In the general case, we can say almost nothing about eigenvalues of the sum of matrices. However, for Hermitian matrices, the situation is more accessible and we have a set of helpful relations. We will present only the main result provided by Weyl [99]; however, it can be extended to more specific cases.
Theorem B7. (Weyl's inequalities)
Let A and B be
$ n \times n $ Hermitian matrices. Then$ \tag{B4} \begin{aligned}[b]& \lambda_{j}(A+B) \leqslant \lambda_{i}(A) + \lambda_{j-i+1}(B) ~{for}~ i \leqslant j \\& \lambda_{j}(A+B) \geqslant \lambda_{i}(A) + \lambda_{j-i+n}(B) ~{for}~ i \geqslant j \end{aligned} $

After some work, the above relations can be transformed to the following form:
$\tag{B5} \vert \lambda_{j}(A+B)-\lambda_{j}(A)\vert \leqslant \rho(B). $

Despite the fact that Weyl's inequalities can be used to estimate eigenvalues of the sum without any restriction to scale of its summands, they give the best results if one of the matrices can be treated as a small additive perturbation of the second matrix, which is a case of the seesaw mechanism.
As singular values are defined as square roots of the Hermitian matrix
$ A^\dagger A $ we should expect that a similar result to Weyl's inequalities is also valid for singular values. However, due to their nonegative nature, we can only estimate the singular values of the sum from above.Theorem B8. (Weyl's inequality for singular values)
Let A and B be a
$ m \times n $ matrices and let$ q = \min \lbrace m,n \rbrace $ . Then$\tag{B6} \sigma_{j}(A+B) \leqslant \sigma_{i}(A) + \sigma_{j-i+1}(B) ~{for}~ i \leqslant j . $

-
The behavior of eigenvectors of a matrix A under a perturbation is much more complicated than that of the eigenvalues. However, in the case of subspaces spanned by eigenvectors there are theorems allowing quantitative prediction of their perturbation. Estimation of the difference between perturbated and unperturbed eigenspaces can be done with the help of orthogonal projections, as the following example shows. Let S be an eigenspace of A spanned by some of its eigenvectors and let
$ S^{\perp} $ be its orthogonal complement. Then A can be decomposed as$\tag{C1} A = E_{0}A_{0}E_{0}^\dagger +E_{1}A_{1}E_{1}^\dagger , $

where
$ E_{0} $ is the orthonormal basis for S and$ E_{1} $ is the orthonormal basis for$ S^{\perp} $ . Similarly, for$ \hat{A} = A+E $ and eigenspace$ \hat{S} $ we have$\tag{C2} \hat{A} = F_{0}\Lambda_{0}F_{0}^\dagger +F_{1}\Lambda_{1}F_{1}^\dagger . $

We would like to know how well vectors in
$ \hat{S} $ approximate vectors in S. The orthogonal projectors onto S and$ \hat{S} $ are given by$ E_{0}E_{0}^\dagger $ and$ F_{0}F_{0}^\dagger $ respectively. Every vector x in S can be written as$ x = E_{0}\alpha $ where$ \alpha \in \mathbb{C}^{dimS} $ and its projection onto$ \hat{S} $ is$ \hat{x} = F_{0}F_{0}^\dagger E_{0}\alpha $ . Thus$\tag{C3} \begin{aligned}[b] \Vert x-\hat{x} \Vert =& \Vert E_{0}\alpha - F_{0}F_{0}^\dagger E_{0}\alpha \Vert = \Vert (I - F_{0}F_{0}^\dagger )E_{0} \alpha \Vert \\ =& \Vert F_{1}F_{1}^\dagger E_{0}\alpha \Vert = \Vert F_{1}^\dagger E_{0}\alpha \Vert. \end{aligned}$

Hence
$ F_{1}^\dagger E_{0} $ tells us how close$ \hat{x} $ is to x.Before we move to the main perturbation theorem, let us state the auxiliary theorem which highlights geometric aspects of the relation between subspaces [100].
Theorem C1. Let
$ X_{1},Y_{1} $ be$ n \times l $ matrices with orthonormal columns. Then there exist$ l \times l $ unitary matrices$ U_{1} $ and$ V_{1} $ , and an$ n \times n $ unitary matrix Q, such that if$ 2l \leqslant n $ , then$\tag{C4} QX_{1}U_{1}= \left( \begin{array}{c} I \\ 0 \\ 0 \end{array} \right) ,$

$\tag{C5} QY_{1}V_{1}= \left( \begin{array}{c} C \\ S \\ 0 \end{array} \right) , $

where
$ C,S $ are diagonal matrices with diagonal entries$ 0 \leqslant c_{1} \leqslant \cdots \leqslant c_{l} \leqslant 1 $ and$ 1 \geqslant s_{1} \geqslant s_{1} \geqslant \cdots \geqslant s_{l} \geqslant 0 $ , respectively, and$ C^{2} + S^{2} = I $ .The relation between matrices C and S resembles the relation between trigonometric functions. This allows us to define angles between subspaces.
Definition 4. Let
$ {\cal{E}} $ and$ {\cal{F}} $ let be$ l- $ dimensional subspaces of$ \mathbb{C}^{n} $ . The angle operator between$ {\cal{E}} $ and$ {\cal{F}} $ is defined as follows$\tag{C6} \Theta({\cal{E}}, {\cal{F}}) = \arcsin S. $

It is a diagonal matrix whose diagonal elements are called the canonical (principal) angles between subspaces
$ {\cal{E}} $ and$ {\cal{F}} $ .Moreover, using the matrix norm we can define the gap between two subspaces.
Definition 5. Let
$ {\cal{E}} $ and$ {\cal{F}} $ be$ l- $ dimensional subspaces of$ \mathbb{C}^{n} $ . Let E and F be orthogonal projections onto$ {\cal{E}} $ and$ {\cal{F}} $ respectively. The distance between subspaces$ {\cal{E}} $ and$ {\cal{F}} $ is defined to be$\tag{C7} \Vert E-F \Vert = \Vert E^{\perp}F \Vert = \Vert \sin \Theta \Vert . $

The perturbation behavior between eigenspaces of Hermitian matrices is described by the renowned Davis-Kahan theorem [101].
Theorem C2. Let A and B be Hermitian operators, and let
$ S_{1} $ be an interval$ [a,b] $ and$ S_{2} $ be the complement of$ (a - \delta, b + \delta) $ in$ \mathbb{R} $ . Let$ E = P_{A}(S_{1}), F^{\perp} = P_{B}(S_{2}) $ be orthogonal projections onto subspaces spanned by eigenvectors of A and B corresponding to eigenvalues from$ S_{1} $ and$ S_{2} $ respectively. Then for every unitarily invariant norm,$ \tag{C8} ||| EF^{\perp}||| \leqslant \frac{1}{\delta} |||E(A-B)F^{\perp}||| \leqslant \frac{1}{\delta} |||A-B|||, $

where
$\tag{C9} \delta = {\rm dist} (\sigma(A),\sigma(B)) = \min \lbrace | \lambda - \mu |: \lambda \in \sigma(A), \mu \in \sigma(B) \rbrace. $

General neutrino mass spectrum and mixing properties in seesaw mechanisms
- Received Date: 2020-09-04
- Available Online: 2021-02-15
Abstract: Neutrinos stand out among the elementary particles because of their unusually small masses. Various seesaw mechanisms attempt to explain this fact. In this work, applying insights from matrix theory, we are in a position to treat variants of seesaw mechanisms in a general manner. Specifically, using Weyl's inequalities, we discuss and rigorously prove under which conditions the seesaw framework leads to a mass spectrum with exactly three light neutrinos. We find an estimate of the mass of heavy neutrinos to be the mass obtained by neglecting light neutrinos, shifted at most by the maximal strength of the coupling to the light neutrino sector. We provide analytical conditions allowing one to prescribe that precisely two out of five neutrinos are heavy. For higher-dimensional cases the inverse eigenvalue methods are used. In particular, for the CP-invariant scenarios we show that if the neutrino sector has a valid mass matrix after neglecting the light ones, i.e. if the respective mass submatrix is positive definite, then large masses are provided by matrices with large elements accumulated on the diagonal. Finally, the Davis-Kahan theorem is used to show how masses affect the rotation of light neutrino eigenvectors from the standard Euclidean basis. This general observation concerning neutrino mixing, together with results on the mass spectrum properties, opens directions for further neutrino physics studies using matrix analysis.



 DownLoad:
DownLoad: